

In-depth look at gRPC for Android


REST is simple and easy to get started. There’re hundreds of tutorials, a search on Medium would give you tons of results, and most developers are using it. When I started reading about gRPC things were not the same. Most of us are using it for the first time, there’re tutorials but you need to look through many until you find the answer you’re looking for, the community is growing but it’s not mature yet, etc.
This article walks you through the most important concepts you need to know to understand gRPC. The concepts range from understanding how an HTTP/2 connection works to learning how to model Protocol Buffers correctly.
By the end of this article, you’ll have learned most of what you need to know to use gRPC effectively in Android.
I’ll be using the following libraries:
build.gradle
com.google.protobuf:protobuf-gradle-plugin:0.8.14
app/build.grdle
api 'io.grpc:grpc-kotlin-stub:1.1.0'api 'io.grpc:grpc-protobuf-lite:1.38.0'implementation 'io.grpc:grpc-android:1.38.0'implementation 'io.grpc:grpc-okhttp:1.38.0'
You can find the source code here.
Everything I say here refers to how the Kotlin library implements the gPRC protocol and it might be different from how other libraries implement it. The content of this article was curated from the resources listed at the end of the page.
HTTP/2
HTTP/2 was introduced to fix many problems HTTP/1 has. The main ones are:
- HTTP/1.x clients need to use multiple connections to achieve concurrency and reduce latency;
- HTTP/1.x does not compress request and response headers, causing unnecessary network traffic;
- HTTP/1.x does not allow effective resource prioritization, resulting in poor use of the underlying TCP connection;
In contrast:
- HTTP/2 reduces latency by enabling full request and response multiplexing,
- HTTP/2 minimizes protocol overhead via efficient compression of HTTP header fields,
- HTTP/2 adds support for request prioritization and server push.
Binary framing layer
HTTP/1 transits its information encoded in US-ASCII. HTTP/2 on the other hand encodes its information in binary. This single change has a big impact on the message size. The HTTP semantics, such as verbs, methods, and headers, are unaffected, but the way they are encoded while in transit is different, this is achieved by adding the binary framing layer.

Both client and server must use the new binary encoding mechanism to understand each other: an HTTP/1.x client won’t understand an HTTP/2 only server, and vice versa.
HTTP/2 also splits its messages into smaller parts called frames, each of which is encoded in binary format.
Streams, messages, and frames
Stream: A bidirectional flow of bytes within an established connection, which may carry one or more messages. Each stream has a unique identifier. A single HTTP/2 connection has one or more streams.
Message: A complete sequence of frames that map to a logical request or response message.
Frame: The smallest unit of communication in HTTP/2, each containing a frame header, which at a minimum identifies the stream to which the frame belongs. The most common headers are HEADERS and DATA.

That’s just a simple explanation of what HTTP/2 is like but it’s enough for understanding the next concept. Now we’re gonna take a look at how gRPC’s channels leverage HTTP/2.
Channel
A channel is basically an interface for sending messages to one or more servers. Channels represent virtual connections to an endpoint, which in reality may be backed by many HTTP/2 connections.
Channels do much more than just sending messages, they do name resolution, establish a TCP connection (with retries and backoff) and TLS handshakes. Channels can also handle errors on connections and reconnect. We’ll see how that happens at the Retry section.
To create a channel you just need the server’s host and port. The context is optional but it helps to manage the channel state.
To create a simple abstraction for users, the gRPC API exposes information about the channel by defining 5 possible states:
CONNECTING
The channel is trying to establish a connection, the steps involved are:
- Name resolution – retrieving the IP address from the hostname;
- TCP connection establishment – establishing a connection using the three-way handshake process;
- TLS handshake if you’re using a secure connection – establishing a secure connection by negotiating what version of SSL/TLS will be used in the session, which cipher suite will encrypt communication, etc.
If any of these steps fail, the channel transitions to TRANSIENT_FAILURE state.
TRANSIENT_FAILURE
Something didn’t go as expected. There has been some failure (such as a TCP 3-way handshake timing out or a socket error).
Channels in this state will eventually switch to the CONNECTING state and try to establish a connection again. You can define a custom retry policy to determine how the retry works.
The amount of time the channel spends on this state increases overtime because retries have exponential backoff.
READY
If the channel has successfully established a connection it transitions from CONNECTING to READY state.
This is the state the channel has to be for it to be used to make RPC calls. In an ideal world this would be the state channels would always stay, but the world is not perfect. If some failure happens the channel will transition to TRANSIENT_FAILURE state.
Even if everything is okay the channel might change its state to IDLE, let’s see why.
IDLE
This is the initial state for channels as defined by ConnectivityStateManager.
It’s a waste of resources for the client and for the server to keep a connection open if no data is being transmitted.
The channel transitions to this state because there has been no activity in the channel for a specified IDLE_TIMEOUT. The default value for IDLE_TIMEOUT is 30 minutes. The minimum value is 1 minute.
The activity can either be a new RPC call or an existing call that has not finished yet. Only channels that are READY or CONNECTING can switch to IDLE.
Any attempt to make a RPC on the channel will push the channel out of this state to CONNECTING.
Channels may receive a GOAWAY from the server to indicate the channel should transition to IDLE to reduce resource waste.
SHUTDOWN
Channels may enter this state either because the application explicitly requested a shutdown or if a non-recoverable error has happened during attempts to connect communicate. Channels that enter this state never leave it.
Any new RPCs should fail immediately. Pending RPCs may continue running till the application cancels them.
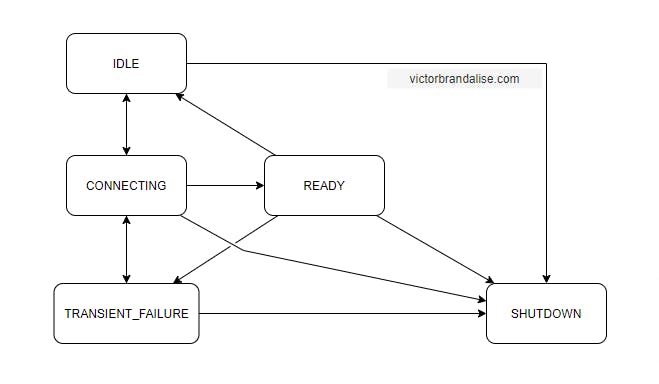
Channel’s States
You can call Channel#getState() to retrieve the channel state.
That’s a good overview of Channels, you know how to create a simple channel and how it behaves in its lifecycle. Now we’re going to see how to configure the channel to change its behavior.
Retry
Unexpected things happen. The connection might be lost, the server may close the connection abruptly, etc. Channels attempt to hide these situations from the user by recovering automatically. I say attempt because some situations are not recoverable and there’s nothing the channel can do about that.
A temporary connectivity loss can be recovered from but if you permanently lose the connection or if the server shuts down, there’s no way to recover.
When retrying, the channel switches from the CONNECTING state to the TRANSIENT_FAILURE state back and forth until the connection is recovered or the retry expires. By default retries are done with exponential backoff.
Some libraries allow you to define a custom retry policy. The Kotlin library allows you to define the max numbers of retries the channel is allowed to do.
By default the channel retries 5 times. If you want to change that you can call AndroidChannelBuilder#maxRetryAttempts(attempts)
If you want to customize other parameters you’ll need to create a custom service configuration. The specification can be found at service_config.proto.
The proto has to be converted to a map style on the Kotlin library. You can learn how to do that here.
Keep Alive
You’ve established a connection to the server. You’ve sent some messages and everything is working fine. Suddenly you try to send another message and it fails, there’re was a problem communicating to the server. If you have retry enabled, the channel will do its job to try to reconnect again but that’s not the best way to handle that.
What if there was an way to discover a problem will happen the next time you send a message? Well that’s not 100% possible but there’s something very close to that in gRPC.
Keep Alive is the feature that allows you to achieve that. Keep Alive sends periodic pings to check if a channel is currently working, that’s done using HTTP/2 PINGs. If the ping is not acknowledged by the peer within a certain timeout period, the channel knows there’s a problem.
Keep Alive is not enabled by default, you can enable it by specifying the keep alive interval on the channel builder.
The above code causes the channel to send a ping to the server every 20 seconds and wait another 5 seconds for a response. If the server doesn’t acknowledge the ping, the channel considers the connection failed, closes the connection, and begins reconnecting.
You might need to call AndroidChannelBuilder#keepAliveWithoutCalls(true) if you’re not actively using the channel but would like it to keep pinging the server.
Subchannel
You’ll not likely work directly with Subchannels but it’s interesting to know why they exist. The Subchannel is used mainly for load balancing. For example, you want to send requests to google.com. The resolver resolves google.com to multiple backend addresses that serve google.com.
For example, let’s suppose there’re 3 servers that serve google.com. The parent Channel will create 3 Subchannels, 1 for each logical connection. You can use the parent channel only and it’ll handle all the load balancing logic.
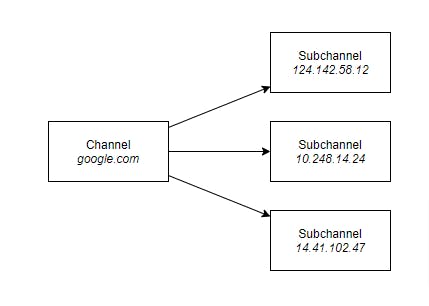
Now that we’ve learned how channels work and that they’re used to transport messages, let’s see how we can send messages.
Protocol Buffers
By default, gRPC uses protocol buffers as the Interface Definition Language (IDL) for describing both the service and messages. It is possible to use other alternatives if desired.
Protocol Buffers are not like JSON where you have data and structure together. It’s closer to Kotlin Interfaces, where you define a protocol specifying methods and fields. The only thing you care about is the protocol, how the protocol will be implemented doesn’t matter to you.
In the example below, I created a protocol to define a book. It has an id to identify each book and its title.
message Book {
int32 id = 1;
string title = 2;
}
The protocol buffer defines an interface, for you to interact with the interface, you need an implemented version in your target language.
If you’re using the protobuf-gradle-plugin, when you build your project, the protobuf plugin will get called and generate the implementation for each proto in Java.
By default the plugin will look for files under app/src/main/proto. The generated files can be found at app/build/generated/source/proto/_buildType_.
There’s much more to Protocol Buffer than we can cover here, if you want to learn more I recommend Protocol Buffer Basics: Kotlin and Language Guide (proto3).
Service
Services are where you define the methods you want to call with their parameters and return types. You can define the API of your service using Protocol Buffers.
You should use CamelCase for both the service name and any RPC method names.
In the example below, I defined an interface that allows me to create books (CreateBook) and list books (ListBooks).
The great thing about the Kotlin library for gRPC is that the generated classes support coroutines.
The above code creates a connection to a server at 127.0.0.1 on port 9000, the connection is then used by a channel that’s passed as argument to create the service. When createBook is called the service dispatches the message to the channel that sends it the to server.
We’ll not look into the server side because this article is focused on Android, but I recommend you looking into that.

Photo by Marc-Olivier Jodoin on Unsplash
RPC
We’ve seen what a service is, now let’s go back and understand it a little bit further. RPCs are in practice plain HTTP/2 streams.
To define a method in Kotlin we use the fun keyword. To define a method in gRPC we use the rpc keyword. The method signature is as follows:
rpc MethodName(Request) returns (Response) {}
There’re 2 kinds of methods in gPRC. Unary and Streaming.
Unary
The client sends a single request to the server and gets a single response back, just like a normal function call. This is what you’ll likely be using the most. It maps closely to a REST request/response.
Streaming
There’re 3 kinds of streaming
- Server streaming RPCs where the client sends a request to the server and gets a stream to read a sequence of messages back.
- Client streaming RPCs where the client writes a sequence of messages and sends them to the server. Once the client has finished writing the messages, it waits for the server to read them and return its response.
- Bidirectional streaming RPCs where both sides send a sequence of messages using a read-write stream. The two streams operate independently, so clients and servers can read and write in whatever order they like.
gRPC guarantees message ordering within an individual RPC call. For example, if the server sends messages 1,2,3 and 4, gRPC guarantees the client will receive them in the same order but doesn’t guarantee the client will actually receive them, the client may actually only receive 1,2 and 3.
Streaming RPCs that return multiple messages from the server won’t retry after the first message has been received. Streaming RPCs that send multiple messages to the server won’t retry if the outgoing messages have exceeded the client’s maximum buffer size.
Unary x Streaming
For lower concurrent requests, both have comparable latencies. However, for higher loads, unary calls are much more performant.
There is no apparent reason we should prefer streams over unary, given using streams comes with problems like complex implementation at the application level and poor load balancing as the client will connect with one server and ignore any new servers and lower resilience to network interruptions.
Success for both parties?
In gRPC, both the client and server make their own independent and local determination about whether the remote procedure call (RPC) was successful. This means their conclusions may not match! An RPC that finished successfully on the server side can fail on the client side.
For example, the server can send the response, but the reply can arrive at the client after their deadline has expired. The client will already have terminated with the status error DEADLINE_EXCEEDED. This should be checked for and managed at the application level.
Best Practices For Protocol Buffers
Most languages have a set of best practices that are followed by developers to improve the code quality. The same applies to Protocol Buffers. Here’re some that I’ve found:
Do not use google.protobuf.Empty as a request or response type. If you use Empty, then adding fields to your request/response will be a breaking API change for all clients and servers.
For custom methods, they should have their own XxxResponse messages even if they are empty, because it is very likely their functionality will grow over time and need to return additional data.
Each enum value should end with a semicolon, not a comma. The zero value enum should be the name of the enum itself followed by the suffix UNSPECIFIED.
enum State {
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
This is my first “big” article. It was really fun writing it, I learned a lot about gRPC. If you have any questions or suggestions, you can contact me on Twitter. I’m open to new ideas, if you want somebody to chat about programming, software architecture, or different approaches in general, I’d be happy to chat with you. Thank you for reading this article.
Other articles
Useful Kotlin Extensions for Android
Android Lifecycle Scenarios – Single and Multi Activities
Resources
Transient fault handling with gRPC retries | Microsoft Docs
Common Design Patterns | Cloud APIs | Google Cloud
Style Guide | Protocol Buffers | Google Developers
gRPC: Top 6 Things that Bite Newbies | by Charles Thayer | Medium
gRPC On HTTP/2: Engineering a robust, high performance protocol | Cloud Native Computing Foundation
HTTP/2: Smarter at scale | Cloud Native Computing Foundation
Introduction to HTTP/2 | Web Fundamentals | Google Developers
High Performance Browser Networking | O’Reilly
The SSL/TLS Handshake: an Overview
Protocol Buffer Basics: Kotlin
Cover Photo by Taylor Vick on Unsplash
The post In-depth look at gRPC for Android first appeared on Victor Brandalise.